
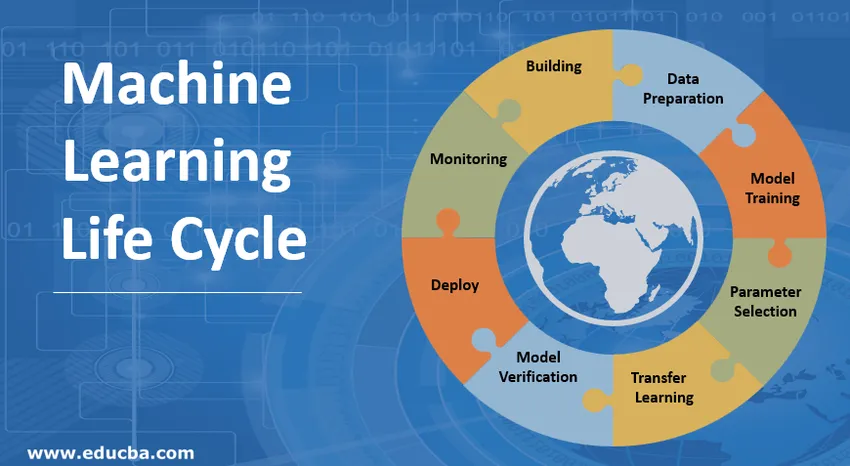
Úvod do životního cyklu strojového učení (ML)
Životní cyklus strojového učení je o získávání znalostí prostřednictvím dat. Životní cyklus strojového učení popisuje třífázový proces používaný vědci a datovými inženýry k vývoji, školení a poskytování modelů. Vývoj, školení a servis modelů strojového učení je výsledkem procesu zvaného životní cyklus strojového učení. Je to systém, který využívá data jako vstup, má schopnost se učit a zlepšovat pomocí algoritmů, aniž by byl k tomu naprogramován. Životní cyklus strojového učení má tři fáze, jak je znázorněno na obrázku níže: vývoj potrubí, školení a odvozování.
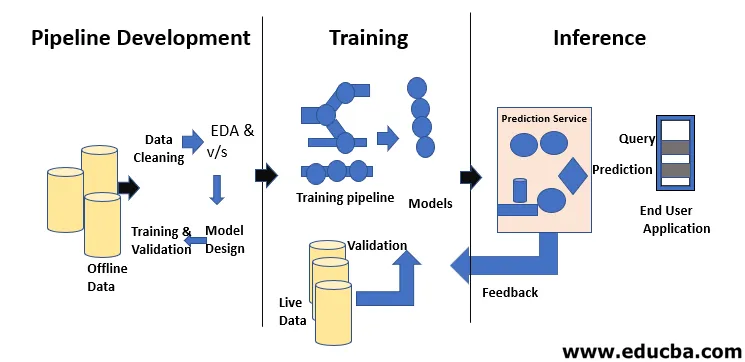
První krok v životním cyklu strojového učení spočívá v transformaci nezpracovaných dat na vyčištěný datový soubor, který je často sdílen a znovu použit. Pokud analytik nebo datový vědec, který narazí na problémy s přijatými daty, musí přistupovat k původním datům a transformačním skriptům. Existuje několik důvodů, proč bychom se mohli vrátit k dřívějším verzím našich modelů a dat. Například nalezení dřívější nejlepší verze může vyžadovat prohledávání mnoha alternativních verzí, protože modely se nevyhnutelně snižují v jejich prediktivní síle. Existuje mnoho důvodů pro tuto degradaci, jako je posun v distribuci dat, který může vést k rychlému poklesu predikční síly jako kompenzace za chyby. Diagnostika tohoto poklesu může vyžadovat porovnání tréninkových dat s živými daty, přeškolení modelu, revizi dřívějších rozhodnutí o návrhu nebo dokonce přepracování modelu.
Poučení z chyb
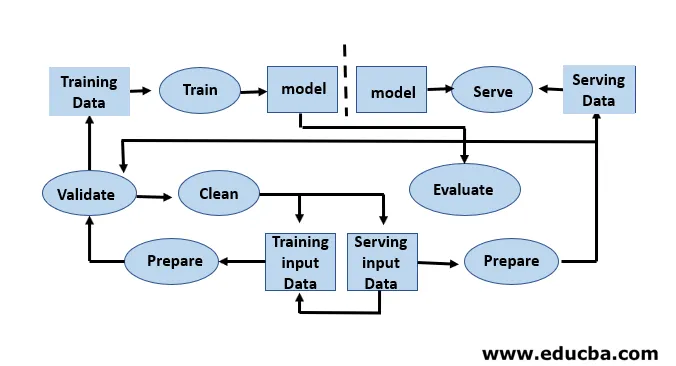
Vývoj modelů vyžaduje samostatné datové sady pro školení a testování. Nadužívání testovacích údajů během tréninku může vést ke špatné generalizaci a výkonu, protože mohou vést k nadměrnému nasazení. Kontext zde hraje zásadní roli, proto je nutné pochopit, která data byla použita k trénování zamýšlených modelů as jakými konfiguracemi. Životní cyklus strojového učení je založen na datech, protože model a výstup výcviku je spojen s údaji, na nichž byl školen. Na následujícím obrázku je uveden přehled potrubí pro učení se strojem z jednoho konce na druhý:
Kroky podílející se na životním cyklu strojového učení
Vývojář strojového učení neustále provádí experimenty s novými datovými sadami, modely, softwarovými knihovnami, vyladěnými parametry za účelem optimalizace a zvýšení přesnosti modelu. Protože výkon modelu závisí zcela na vstupních datech a procesu školení.
1. Vytvoření modelu učení stroje
Tento krok rozhoduje o typu modelu na základě aplikace. Zjistí také, že aplikace modelu ve fázi učení modelu tak, aby mohly být správně navrženy podle potřeby zamýšlené aplikace. K dispozici je celá řada modelů strojového učení, jako je model pod dohledem, model bez dozoru, klasifikační modely, regresní modely, shlukové modely a modely učení se zesílením. Podrobný přehled je znázorněn na obrázku níže:
2. Příprava dat
Jako vstup pro účely strojového učení lze použít různé údaje. Tato data mohou pocházet z mnoha zdrojů, jako jsou podniky, farmaceutické společnosti, zařízení internetu věcí, podniky, banky, nemocnice atd. Ve stadiu učení stroje jsou poskytovány velké objemy dat, protože se zvyšujícím se počtem dat se sbližuje s přináší požadované výsledky. Tato výstupní data mohou být použita pro analýzu nebo jako vstup do jiných aplikací nebo systémů strojového učení, pro které bude fungovat jako zárodek.
3. Školení modelu
Tato fáze se zabývá vytvořením modelu z dat, která mu byla předána. V této fázi se část tréninkových dat používá k nalezení parametrů modelu, jako jsou koeficienty polynomu nebo hmotnosti strojového učení, což pomáhá minimalizovat chybu pro daný soubor dat. Zbývající data jsou pak použita k testování modelu. Tyto dva kroky se obvykle opakují několikrát, aby se zlepšil výkon modelu.
4. Výběr parametrů
Zahrnuje výběr parametrů spojených s tréninkem, které se také nazývají hyperparametry. Tyto parametry řídí efektivitu tréninkového procesu, a tedy i výkon modelu závisí na tom. Jsou velmi důležité pro úspěšnou výrobu modelu strojového učení.
5. Přenos učení
Protože existuje mnoho výhod v opakovaném použití modelů strojového učení napříč různými doménami. Navzdory skutečnosti, že model nemůže být přenesen přímo mezi různými doménami, je proto používán pro poskytnutí výchozího materiálu pro zahájení výcviku modelu další fáze. Výrazně tak zkracuje dobu tréninku.
6. Ověření modelu
Vstupem této fáze je trénovaný model vytvořený fází učení modelu a výstupem je ověřený model, který poskytuje dostatečné informace, které uživatelům umožňují určit, zda je model vhodný pro zamýšlené použití. Tato fáze životního cyklu strojového učení se tedy týká skutečnosti, že model pracuje správně, když je zpracován se vstupy, které nejsou vidět.
7. Nasadit model strojového učení
V této fázi životního cyklu strojového učení uplatňujeme integraci modelů strojového učení do procesů a aplikací. Konečným cílem této fáze je správná funkčnost modelu po nasazení. Modely by měly být rozmístěny takovým způsobem, aby mohly být použity pro odvozování a aby byly pravidelně aktualizovány.
8. Monitorování
Zahrnuje zahrnutí bezpečnostních opatření pro zajištění řádného fungování modelu během jeho životnosti. Aby k tomu došlo, je nutná správná správa a aktualizace.
Výhody životního cyklu strojového učení
Strojové učení poskytuje výhody síly, rychlosti, účinnosti a inteligence díky učení, aniž by je výslovně programovalo do aplikace. Poskytuje příležitosti pro lepší výkon, produktivitu a robustnost.
Závěr - strojový životní cyklus
Systémy strojového učení se stávají důležitějšími každým dnem, protože množství dat zahrnutých v různých aplikacích rychle roste. Technologie strojového učení je srdcem inteligentních zařízení, domácích spotřebičů a online služeb. Úspěch strojového učení lze dále rozšířit na systémy kritické z hlediska bezpečnosti, správu dat, vysoce výkonné výpočty, které mají velký potenciál pro aplikační domény.
Doporučené články
Toto je průvodce životním cyklem strojového učení. Zde diskutujeme úvod, poučení z chyb, kroky zapojené do životního cyklu strojového učení a výhody. Další informace naleznete také v dalších navrhovaných článcích -
- Umělé zpravodajské společnosti
- Analýza sady QlikView
- Ekosystém IoT
- Cassandra Data Modeling