

Rozdíl mezi Apache Nifi a Apache Spark
Až po dlouhou dobu, kdy byla těžká práce, kterou bylo třeba dokončit, se lidé spoléhali na koně, kteří tahali těžké náklady, udržovali rychlost nebo cokoli jiného mezi tím. Ne všichni koně však byli vhodní pro každý úkol. Totéž platí pro technologii dnes. S příchodem nových technologií, které se odlévají každý den, je nesmírně důležité znát jejich skutečné aplikace. Dvě takové technologie jsou Apache Nifi a Apache Spark a budeme o nich studovat v tomto příspěvku.
Apache Spark je framework pro výpočet clusterů s otevřeným zdrojovým kódem, jehož cílem je poskytnout rozhraní pro programování celé sady klastrů s implicitní odolností proti chybám a paralelizací dat. Využívá RDD (Resilient Distributed Datasets) a zpracovává data ve formě Diskretizovaných toků, které jsou dále využívány pro analytické účely.
Apache Nifi (což je krátká forma NiagaraFiles) je další softwarový projekt, jehož cílem je automatizovat tok dat mezi softwarovými systémy. Návrh je založen na programovém modelu založeném na toku, který poskytuje funkce, které zahrnují práci se schopnostmi klastrů. Je to snadno použitelný, spolehlivý a výkonný systém pro zpracování a distribuci dat. Podporuje škálovatelné směrované grafy pro směrování dat, zprostředkování systému a logiku transformace. Pojďme diskutovat o porovnání obou témat.
Srovnání hlava-hlava mezi Apache Nifi vs Apache Spark (Infographics)
Níže je prvních 9 srovnání mezi Apache Nifi vs Apache Spark
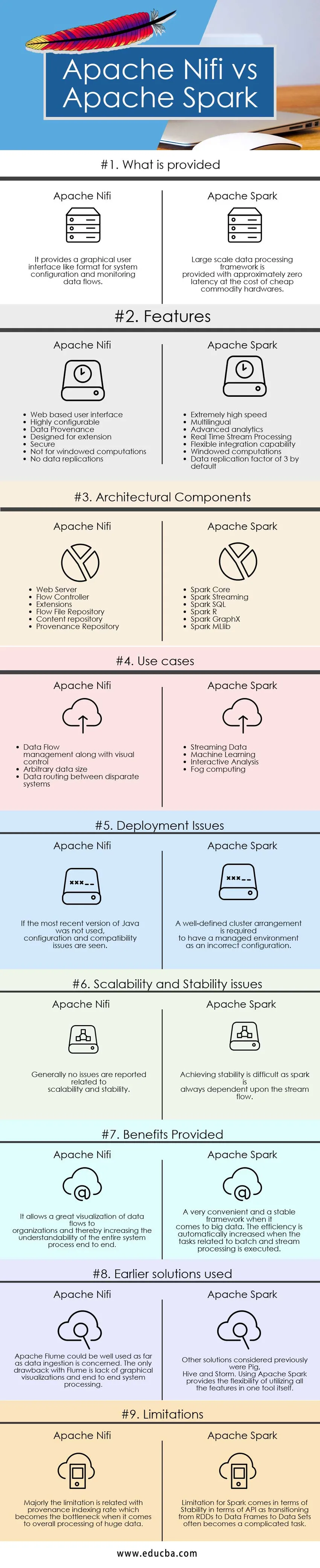
Klíčové rozdíly mezi Apache Nifi a Apache Spark
Rozdíly mezi Apache Nifi a Apache Spark jsou vysvětleny v následujících bodech:
- Apache Nifi je nástroj pro příjem dat, který se používá k poskytování snadno použitelného, výkonného a spolehlivého systému, takže zpracování a distribuce dat prostřednictvím zdrojů je snadné, zatímco Apache Spark je extrémně rychlá technologie klastrových počítačů, která je navržena pro rychlejší výpočet pomocí efektivní využití interaktivních dotazů, ve správě paměti a ve zpracování toku.
- Apache Nifi pracuje v samostatném režimu a v clusterovém režimu, zatímco Apache Spark funguje dobře v místním nebo samostatném režimu, Mesos, Yarn a dalších druzích režimů velkých datových clusterů.
- Mezi vlastnosti Apache Nifi patří zaručené doručování dat, efektivní ukládání dat do vyrovnávací paměti, prioritní fronty, toky specifické QoS, poskytování dat, obnova vyrovnávací paměti, vizuální příkazy a řízení, tokové šablony, zabezpečení, funkce paralelního streamování, zatímco funkce apache jiskry zahrnují blesky rychle rychlost zpracování, vícejazyčné, výpočetní v paměti, efektivní využití hardwarových systémů komodit, pokročilá analýza, efektivní integrační schopnost.
- Apache Nifi umožňuje lepší čitelnost a celkové porozumění systému poskytováním vizualizačních funkcí a funkcí drag and drop. Tok dat lze snadno řídit a řídit pomocí konvenčních technik a procesů, zatímco v případě Apache Spark je pro zobrazení těchto druhů vizualizací zapotřebí systém správy clusterů, jako je Ambari. Apache Spark sám o sobě neposkytuje vizualizační schopnosti a je dobrý pouze pokud jde o programování. Je to zdaleka velmi pohodlný a stabilní systém pro zpracování obrovského množství dat.
- Omezení Apache Nifi souvisí s tím, jaká je jeho výhoda. Jediná funkce drag and drop poskytuje omezení nemožnosti škálovat a poskytovat robustnost, pokud jde o jeho integraci s dalšími komponenty a nástroji, zatímco v případě Apache Spark primární omezení přichází s použitím rozsáhlého komoditního hardwaru a jejich správou se občas stává únavným úkolem. Další ohlášené omezení přichází spolu s jeho schopnostmi streamování souvisejícími s diskrétním tokem a oknem nebo dávkovým tokem, kde transformace RDD na datový rámec a datové sady poskytuje občas nestabilitu.
Tabulka porovnání Apache Nifi vs Apache Spark
| Základy srovnání | Apache Nifi | Apache Spark |
| Co je k dispozici | Poskytuje grafické uživatelské rozhraní jako formát pro konfiguraci systému a monitorování datových toků. | Rámec pro rozsáhlé zpracování dat je poskytován s přibližně nulovou latencí za cenu levného komoditního hardwaru. |
| Funkce |
|
|
| Architektonické komponenty |
|
|
| Případy užití |
|
|
| Problémy s nasazením | Pokud nebyla použita nejnovější verze Java, jsou vidět problémy s konfigurací a kompatibilitou | Dobře definované uspořádání clusteru je vyžadováno, aby bylo spravované prostředí jako nesprávná konfigurace |
| Škálovatelnost a problémy se stabilitou | Obecně nejsou hlášeny žádné problémy související se škálovatelností a stabilitou | Dosažení stability je obtížné, protože jiskra je vždy závislá na toku proudu. |
| Poskytnuté výhody | Umožňuje skvělou vizualizaci datových toků organizacím a tím zvyšuje srozumitelnost celého procesu systému od začátku do konce | Velmi pohodlný a stabilní rámec, pokud jde o velká data. Účinnost je automaticky zvýšena, když jsou prováděny úkoly související se zpracováním dávky a proudu. |
| Použitá dřívější řešení | Pokud jde o příjem dat, může být Apache Flume dobře použit. Jedinou nevýhodou aplikace Flume je nedostatek grafických vizualizací a zpracování systému od začátku do konce | Dalšími dříve uvažovanými řešeními byly Prase, Úl a Bouře. Použití Apache Spark poskytuje flexibilitu využití všech funkcí v jednom nástroji samotném. |
| Omezení | Omezení se týká hlavně míry indexace provenience, která se stává problémem, pokud jde o celkové zpracování obrovských dat | Omezení pro Spark přichází z hlediska stability ve smyslu API, protože přechod z RDD do datových rámců do datových sad se často stává komplikovaným úkolem. |
Závěr - Apache Nifi vs Apache Spark
Na závěr příspěvku lze říci, že Apache Spark je těžký válečník, zatímco Apache Nifi je hbitý dostihový kůň. Oba mají své vlastní výhody a omezení, která mají být použita v jejich příslušných oblastech. Musíte se rozhodnout, který nástroj je vhodný pro vaše podnikání. Zůstaňte naladěni na náš blog, kde naleznete další články týkající se novějších technologií velkých dat.
Doporučený článek
Toto byl průvodce Apache Nifi vs Apache Spark, jejich význam, srovnání hlava-hlava, hlavní rozdíly, srovnávací tabulka a závěr. Další informace naleznete také v následujících článcích -
- Apache Hadoop vs Apache Spark | Top 10 srovnání, které musíte znát!
- Apache Storm vs Apache Spark - Naučte se 15 užitečných rozdílů
- 7 důležitých věcí o Apache Spark (Průvodce)
- 15 nejlepších věcí, které potřebujete vědět o MapReduce vs Spark