
Co je Cassandra?
Cassandra je databáze NoSQL, která poskytuje distribuovanou databázi typu peer to peer. Běží na clusteru, který má homogenní uzly. Je vyroben tak, že dokáže zpracovat velké objemy dat. Při manipulaci s těmito údaji by mělo být také možné zajistit vysokou schopnost. Cassandra poskytuje vysokou úroveň, pokud jde o operace čtení a zápisu. Architektura clusteru Cassandra nemá žádné pány, otroky ani konkrétní vůdce. Tímto způsobem zajišťuje, že nedochází k jedinému bodu selhání. Podívejme se podrobně na architekturu.
Cassandra Architecture
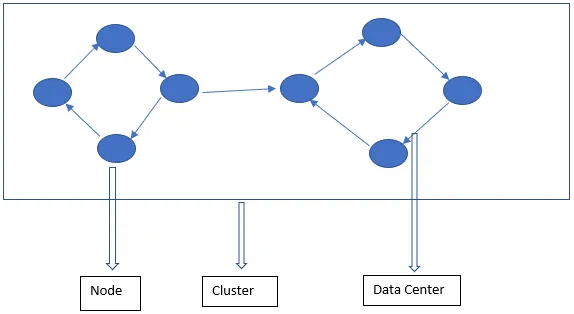
Cassandra Architecture se skládá hlavně z uzlu, clusteru a datového centra. Kromě toho existují i další komponenty. Cassandra je řádkově uložená databáze. Umožňuje autorizovaným uživatelům připojit se k libovolnému uzlu v libovolném datovém centru pomocí CQL.
Klíčové struktury v Cassandře
Toto jsou následující klíčové struktury v Cassandře:
- Uzel - zde se ukládají data. Je to nejzákladnější součást Cassandry. Lze to považovat za jediný server ve stojanu. Zajišťuje, aby nedošlo k jedinému bodu selhání.
- Datové centrum - Datové centrum je kolekce uzlů. Může to být buď fyzická, nebo virtuální. V závislosti na pracovní zátěži jsou datová centra rozdělena a vybrána. O faktoru replikace se rozhoduje na základě datového centra. V závislosti na tomto replikačním faktoru lze data zapisovat do různých datových center.
- Cluster - Cluster zahrnuje jedno nebo více datových center. Klastry se obvykle rozpínají na různých fyzických místech.
Kromě těchto jsou další komponenty, které hrají roli v Cassandře, uvedeny níže.
1. Commit Log
Data, která se zavázala udržovat trvanlivost dat, se ukládají do protokolu potvrzení. Data jsou přesunuta do tabulky seřazených řetězců (vysvětleno dále). Jakmile je tento pohyb dokončen, může být protokol potvrzení archivován, odstraněn nebo recyklován.
2. Tabulka SS
Tato tabulka, jak je uvedeno v předchozím bodě, ukládá tabulky protokolu nebo paměti v pravidelných intervalech. Je to neměnný datový soubor. Tabulky SS mohou ukládat data často sekvenčním způsobem. Připojují data a uchovávají informace pro každou tabulku Cassandra.
3. Tabulka CQL
Tabulka dotazů Cassandra je kolekce uspořádaných sloupců, které mohou načíst řádek z této tabulky. V této tabulce jsou uloženy sloupce, kde lze data získat pomocí primárního klíče.
4. Bloom filtr
Jde o jednoduchý druh mezipaměti, kde jsou pro testování uloženy nedeterministické algoritmy. Kontroluje, zda je prvek členem sady nebo ne. K těmto filtrům se obvykle přistupuje po každém spuštěném dotazu.
Klíčové komponenty pro konfiguraci Cassandry
V Cassandře jsou následující komponenty:
1. Klebety
- Jak název napovídá, musí existovat komunikace mezi vrstevníky, aby bylo možné zjistit a sdílet polohu a stav informací o všech uzlech.
- Tato informace by měla zůstat v místní, aby každý uzel mohl tyto informace použít, jakmile se uzel musí restartovat. Uzly objevují informace o jiných uzlech výměnou informací.
- To lze provést maximálně pro tři uzly. Informace nejsou sdíleny s každým uzlem, který je přítomen v klastru nebo datovém centru. Informace jsou sdíleny s několika uzly, ale nakonec informace o stavu procházejí skrz klastr.
2. Partitioner
- Rozdělovač rozhodne, který uzel musí přijmout první repliku všech dat. Je také zodpovědný za péči o distribuci těchto replik.
- Určuje, který uzel by měl mít jakou replikaci v klastru. Každý řádek dat by měl být jednoznačně identifikován. To lze provést pomocí primárního klíče nebo klíče oddílu.
- Rozdělovač je hash funkce, která pomáhá získat token z primárního klíče libovolného řádku. Každý uzel má přiřazenou hodnotu num_token, kterou lze nastavit jako rozdělovač.
- Generovaná hodnota tokenu pomáhá při určování, který uzel přijímá repliku řádků.
3. Replikační faktor
- Tento faktor určuje celkový počet replik přítomných v klastru. Pokud je faktor replikace 1, pak existuje pouze jedna kopie každého řádku na jednom uzlu.
- Podobně, pokud je replikační faktor dvě, budou udržovány dvě kopie, kde je každá kopie přítomna v jiném uzlu. Jak již bylo zmíněno dříve, v Cassandře neexistuje žádná architektura master-slave. Každá kopie je důležitá.
- Faktor replikace je definován pro každé datové centrum. Tento faktor by měl být větší než jeden, ale ne větší než počet uzlů přítomných v klastru.
4. Snitch
- Replikační strategie, která pomáhá při získávání místa, kde mají být repliky umístěny pro skupinu počítačů v datovém centru a stojanu, se nazývá Snitch.
- Existuje dynamická vrstva, která pomáhá při sledování a výkonu a pomáhá při výběru nejlepší repliky, ze které lze data číst. Úplet by měl být konfigurován pouze při vytvoření klastru.
- Pro většinu nasazení má výchozí hodnoty povoleny. Změny konfigurace lze provést v souboru Cassandra.yml, kde je pro každý uzel přítomen práh dynamického pletení.
5. Merkle Tree
- V datových blocích mohou být rozdíly. Aby bylo možné snadno najít rozdíly, je Merkle strom hash strom, který k tomu pomáhá.
- Listové uzly hašovacího stromu obsahují hashe samostatných datových bloků a nadřazené uzly mají informace nebo ukládají hash svých dětí.
- Pomocí této techniky je snazší najít rozdíly mezi přítomnými uzly.
6. Paměťová tabulka
- Tato tabulka obsahuje informace o mezipaměti, jejíž data dosud nejsou vyprázdněna a jsou uložena v paměti.
Závěr
Cassandra je databáze NoSQL, která je užitečná při zpracování obrovského množství dat. Nemá typickou architekturu master-slave, a proto jsou všechny uzly stejně důležité. Uzly mají repliky napříč klastrem podle replikačního faktoru. Tím je zajištěna konzistence a trvanlivost dat. U všech těchto funkcí je jasné, že Cassandra je velmi užitečná pro velká data. Cassandra je tedy odolný, rychlý, protože je distribuován a spolehlivý.
Doporučené články
Toto je průvodce architekturou Cassandra. Zde diskutujeme o úvodu, architektuře Cassandra, klíčové struktuře a klíčových komponentách Cassandry. Můžete si také prohlédnout naše další doporučené články -
- Přehled architektury Kubernetes
- Co je architektura velkých dat?
- Funkce přidané do architektury AutoCADu
- Architektura cloud computingu