

Úvod do architektury HBase
HBase je open-source, distribuovaný systém ukládání dat s klíčovou hodnotou a sloupec-orientovaná databáze s vysokým výstupem zápisu a náhodným čtením s nízkou latencí. Pomocí HBase můžeme provádět online analýzu v reálném čase. Architektura HBase má silnou náhodnou čitelnost. V HBase jsou data fyzicky rozdělena do tzv. Regionů. Každá oblast je hostována jedním regionálním serverem a za každý regionový server odpovídá jedna nebo více oblastí. Architektura HBase se skládá ze serverů typu master-slave. Klastr HBase má jeden hlavní uzel nazvaný HMaster a několik regionálních serverů nazývaných HRegion Server (HRegion Server). V každém regionálním serveru je více regionů - regionů.
Mechanismus ukládání HDFS

V systému HDFS jsou data uložena v tabulce, jak je uvedeno výše.
Každý řádek má klíč.
Sloupec: Jedná se o soubor dat, který patří do jedné skupiny sloupců a je obsažen uvnitř řádku.
Rodina sloupců: Každá rodina sloupců se skládá z jednoho nebo více sloupců.
Každá tabulka obsahuje kolekci Rodiny sloupců. Tyto sloupce nejsou součástí schématu.
HBase má dynamické sloupce. Různé buňky mohou mít různé sloupce, protože názvy sloupců jsou kódovány uvnitř buněk
Kvalifikátor sloupce: Název sloupce se nazývá Kvalifikátor sloupce.
Komponenty architektury HBase
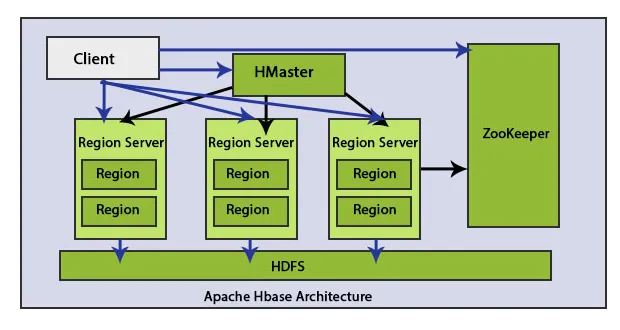
V architektuře HBase jsou hlavní prvky: HMaster a Region Server. Ukládání dat o regionální HBase.
1. HMaster
Uzel HMaster je lehký a používá se pro přiřazení oblasti k oblasti serveru.
Hmaster má několik hlavních povinností, které jsou:
- Provádění některých administrativních úkolů, včetně načítání, vyvážení, vytváření dat, aktualizace, mazání atd.
Odpovědný za změny ve schématu nebo úpravy dat META podle směru klientské aplikace
- Mnoho práce DDL na tabulkách HBase je zpracováváno HMasterem.
Některé metody, které HMaster Interface vystavuje, jsou hlavně. META datově orientované metody.
- Tabulka (vytvoření, odstranění, povolení, zakázání, odstranění tabulky)
- ColumnFamily (přidat sloupec, upravit sloupec)
- Region (přesunout, přiřadit)
Klient komunikuje s HMaster i ZooKeeper obousměrně. Přímo kontaktuje servery HRegion a čte a zapisuje operace. HMaster přiřazuje regiony serverům v regionu a následně kontroluje zdravotní stav regionálních serverů.
2. Region Server
Hrubou představu o regionálním serveru můžeme získat pomocí následujícího diagramu.

Servery regionů jsou pracovní uzly, které zpracovávají požadavky zákazníků na čtení, zápis, aktualizaci a mazání. Region Server je lehký, běží na všech uzlech clusteru Hadoop. Hlavním úkolem regionálního serveru je ukládat data v oblastech a provádět požadavky zákazníků. Dalším důležitým úkolem serveru HBase Region je použití metody Auto-Sharding k vyrovnání zátěže dynamickým rozdělením tabulky HBase, když se po vložení dat stane příliš velkým.
HMaster může kontaktovat více serverů HRegion a provádět následující funkce:
- Správa a regiony hostings
- Automaticky rozdělené oblasti
- Vyřizování žádostí o čtení a psaní
- Přímá komunikace se zákazníkem
3. HDFS
HDFS znamená systém distribuovaných souborů Hadoop. Ukládá každý soubor v několika blocích a replikuje bloky napříč klastrem Hadoop, aby byla zachována odolnost proti chybám. HDFS poskytuje vysokou odolnost proti chybám a pracuje s nízkonákladovými materiály. Použití levného komoditního hardwaru k přidání uzlů do clusteru a zpracování a uložení poskytne zákazníkovi lepší výsledky než stávající hardware. HDFS kontaktuje komponenty HBase a distribuuje spousty dat.
4. Zookeeper
Zookeeper je open-source projekt. HMaster a HRegionServers se registrují u ZooKeeper.
Poskytuje různé služby, jako je údržba konfiguračních informací, pojmenování, poskytování distribuované synchronizace atd. Distribuovaná synchronizace je proces poskytování koordinačních služeb mezi uzly pro přístup ke spuštěným aplikacím. Má efemérní uzly, které představují servery regionu. Hlavní servery používají tyto uzly k vyhledání dostupných serverů.
Tyto uzly se také používají ke sledování síťových oddílů a selhání serveru. Zookeeper je médium interakce mezi serverem Klientské oblasti. Pokud chce klient komunikovat s regionálním serverem, pak je komunikačním prostředkem mezi nimi zookeeper.
Jak inicializuje vyhledávání v architektuře HBase
Jak víte, umístění tabulky META ukládá Zookeeper. Pokaždé, když se zákazník přiblíží nebo píše žádosti o HBase, postup je následující.
Zákazník zjistí od ZooKeeper, jak je umístit na stůl META. Klient poté od nich požádá o příslušný klíč řádku META k přístupu k umístění serveru regionu. Při umístění tabulky META zákazník ukládá tyto informace do mezipaměti. Zákazník se na ně nebude odvolávat na tabulku META, dokud a pokud se oblast nepřesune nebo neposune. Poté bude server META znovu požádán a mezipaměť bude aktualizována. Jako vždy zákazníci neztrácejí čas hledáním umístění regionálního serveru na serveru META, takže šetří čas a zrychluje proces vyhledávání.
Funkce
S Hadoopem lze snadno integrovat ze zdroje i cíle.
Distribuované úložiště jako HDFS je podporováno.
Má funkci náhodného přístupu pomocí interní tabulky Hash k ukládání dat pro rychlejší vyhledávání v souborech HDFS.
Výhody architektury HBase
- Mohou ukládat velké datové sady
- Můžeme sdílet databázi
- Gigabajty k petabytům nákladově efektivní
- Vysoká dostupnost díky replikaci a selhání
Nevýhody architektury HBase
- Struktura SQL nepodporuje
- Nepodporuje transakci
- Pouze s tříděným klíčem
- Problémy s klastrovou pamětí
Závěr
HBase je jednou z distribuovaných databází NonSql orientovaných na sloupce v apache. Při porovnání s Hadoopem nebo Hive má HBase lepší výsledky při načítání méně záznamů. V tomto článku jsme tedy probrali architekturu HBase a její důležité komponenty.
Doporučené články
Toto byl průvodce HBase Architecture. Zde jsme diskutovali o konceptu, komponentách, vlastnostech, výhodách a nevýhodách. Další informace naleznete také v našich dalších doporučených článcích -
- Co je technologie velkých dat?
- HDFS vs HBase, který je lepší
- Co je to jazyk sestavení?
- Úvod do HTML