
Úvod do souborů R CSV
Soubory CSV se běžně používají k ukládání informací v tabulkovém formátu, přičemž každý řádek je záznamem dat. Abychom mohli číst, psát nebo manipulovat s daty v R, musíme mít k dispozici některá data. Data lze nalézt na internetu nebo je lze získat z různých zdrojů, jako jsou průzkumy. Pomocí R lze číst, psát a upravovat data uložená v externím prostředí. R umí číst a zapisovat data z různých formátů, jako je XML, CSV a Excel. V tomto článku se podíváme, jak lze R použít ke čtení, zápisu a provádění různých operací se soubory CSV.
Vytváření souboru CSV v R
V této části se podíváme, jak lze datový rámec vytvořit a exportovat do souboru CSV v R. V první části vytvoříme datový rámec, který se skládá z proměnných zaměstnanec a příslušného platu.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
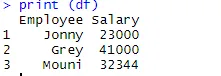
Jakmile je datový rámec vytvořen, je čas, abychom použili exportní funkci R k vytvoření CSV souboru v R. Aby bylo možné exportovat datový rámec do CSV, můžeme použít níže uvedený kód.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
Ve výše uvedeném řádku kódu jsme poskytli adresář cesty pro naši datovou slávu a uložili dataframe ve formátu CSV. Ve výše uvedeném případě byl soubor CSV uložen na mou osobní plochu. Tento konkrétní soubor bude použit v našem tutoriálu pro provádění více operací.
Čtení souborů CSV v R
Při provádění analýzy pomocí R jsme v mnoha případech povinni číst data ze souboru CSV. R je velmi spolehlivý při čtení souborů CSV. Ve výše uvedeném příkladu jsme vytvořili soubor, který použijeme ke čtení pomocí příkazu read.csv. Níže je uveden příklad, jak toho dosáhnout v R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Výše uvedený příkaz přečte soubor Employee.csv, který je k dispozici na ploše a zobrazí jej v R studio. Příkaz záhlaví znamená, že záhlaví je k dispozici pro datovou sadu a příkaz sep znamená, že data jsou oddělena čárkami.
Zapisujte soubory CSV do R
Zápis do souboru CSV je jednou z nejužitečnějších funkcí dostupných v R pro datového analytika. To lze použít k zápisu upraveného souboru CSV do nového souboru CSV za účelem analýzy dat. Příkaz Write.csv se používá k zápisu souboru do CSV.
V níže uvedeném kódu df v datovém rámci, ve kterém jsou naše data k dispozici, se připojením určuje, že nový soubor je vytvořen místo připojování nebo přepisování ve starém souboru. Připojit false navrhuje nový soubor CSV. Sep představuje pole oddělené čárkou.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
Provoz CSV
Operace CSV jsou vyžadovány pro kontrolu dat, jakmile jsou načtena do systému. R má několik vestavěných funkcí pro ověření a kontrolu dat. Tyto operace poskytují úplné informace týkající se souboru dat.
Jedním z nejčastěji používaných příkazů je shrnutí.
> summary(df)
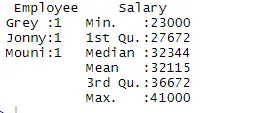
Příkaz shrnutí nám poskytuje statistiku sloupců. Numerická proměnná je popsána statistickým způsobem, který zahrnuje statistické výsledky jako průměr, min, medián a max. Ve výše uvedeném příkladu jsou oddělené dvě proměnné, kterými jsou Zaměstnanec a Plat, a jsou nám ukázány statistiky pro numerickou proměnnou, kterou je Mzda.
Příkaz View () se používá k otevření datové sady na jiné kartě a ověření ručně.
> View(df)

Funkce Str poskytne uživatelům další podrobnosti týkající se sloupce datové sady. V níže uvedeném příkladu vidíme, že proměnná Employee má jako datový typ Factor a proměnná Salary má jako datový typ int (integer).
> str(df)

V mnoha případech budeme muset vidět celkový počet dostupných řádků v případě velkého datového souboru, pro který můžeme použít příkaz nrow (). Viz níže uvedený příklad.
> # to show the total number of rows in the dataset
> nrow(df)

Podobným způsobem, jak zobrazit celkový počet sloupců, můžeme použít příkaz ncol ()
> ncol(df)

R nám umožňuje zobrazit požadovaný počet řádků pomocí příkazu níže. Když je jejich počet řádků k dispozici v datové sadě, můžeme určit rozsah řádků, které se mají zobrazit.
> # to display first 2 rows of the data
> df(1:2, )

Operace dat se provádí na velkém datovém souboru. Pro ilustraci jsem stáhl datový soubor s otevřeným zdrojovým kódem NI z internetu.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
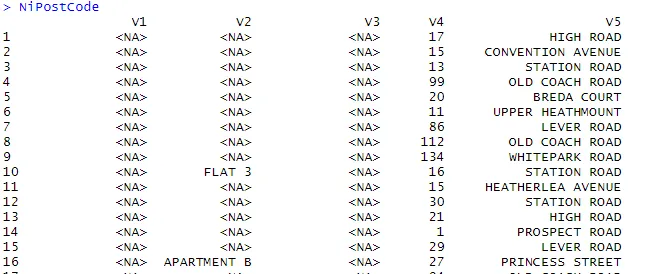
Ve výše uvedené sadě dat vidíme, že chybí názvy záhlaví a existuje mnoho nulových hodnot. Aby byl datový soubor připraven k analýze, musí být vyčištěn. V dalším kroku budou záhlaví odpovídajícím způsobem pojmenována.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Nyní spočítáme počet chybějících hodnot v datovém rámci a podle toho je odeberte.
> # count of all missing values
> table(is.na (NiPostCode))

Z výše uvedeného příkazu vidíme, že celkový počet mezer nebo NA v datovém rámci je blízko 5445148. Odstranění všech nulových hodnot povede ke ztrátě obrovského množství dat, proto je moudré odstranit sloupce, kde je více než polovina 50% dat chybí.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Závěr
V tomto tutoriálu jsme viděli, jak lze soubory CSV vytvářet, číst a přidávat pomocí operací v R. Naučili jsme se, jak vytvořit nový dataset v R a poté jej importovat do formátu CSV. Dále jsme viděli několik operací, jako je přejmenování záhlaví a počítání počtu řádků a sloupců.
Doporučené články
Toto je průvodce soubory R CSV. Zde diskutujeme o vytváření, čtení a zápisu CSV souboru v R s CSV Operations. Další informace naleznete také v následujícím článku -
- JSON vs CSV
- Proces dolování dat
- Kariéra v analýze dat
- Excel vs CSV