

Rozdíl mezi těžbou dat a strojovým učením
Dolování dat se týká získávání znalostí z velkého množství dat. Dolování dat je proces objevování různých typů vzorů, které jsou zděděny v datech a které jsou přesné, nové a užitečné. Dolování dat je podmnožinou podnikové analýzy, je podobné experimentálnímu výzkumu. Původy dolování dat jsou databáze, statistiky. Strojové učení zahrnuje algoritmus, který se automaticky zlepšuje na základě zkušeností založených na datech. Strojové učení je způsob, jak objevit nový algoritmus ze zkušenosti. Strojové učení zahrnuje studium algoritmů, které mohou automaticky extrahovat informace. Strojové učení používá techniky dolování dat a další algoritmus učení k vytváření modelů toho, co se děje za některými daty, aby bylo možné předpovídat budoucí výsledky.
Podívejme se na tento příspěvek podrobně dolování dat a strojové učení.
Srovnání mezi hlavami mezi dolováním dat a strojovým učením (infografika)
Níže je 10 nejlepších srovnání mezi těžbou dat a strojovým učením
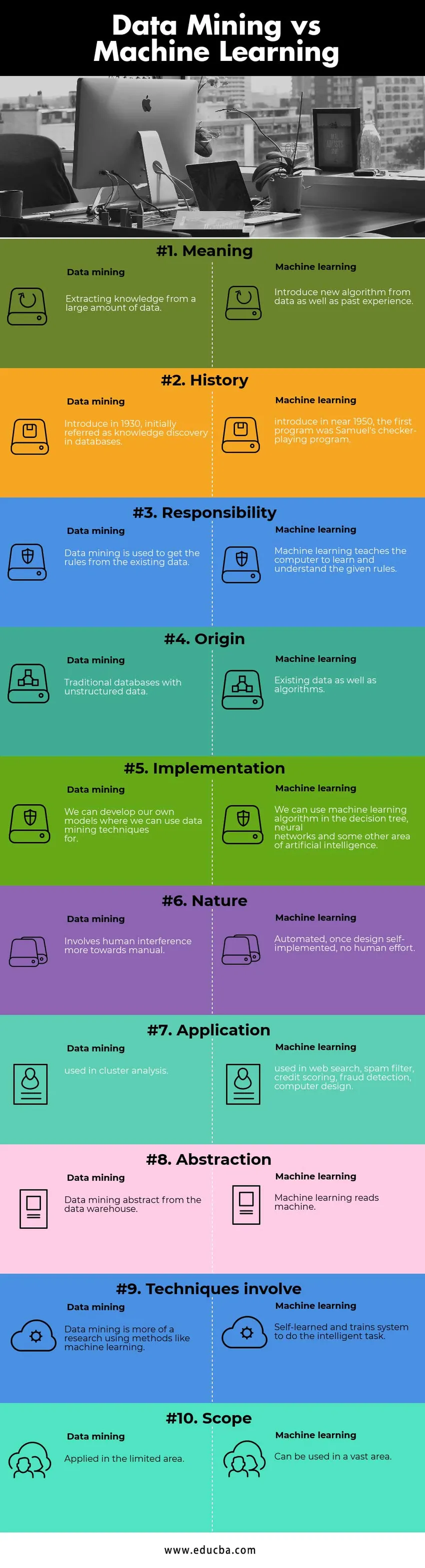 Klíčový rozdíl mezi těžbou dat a strojovým učením
Klíčový rozdíl mezi těžbou dat a strojovým učením
- Pro implementaci technik dolování dat použila dvoukomponentní první, která je databáze a druhá je strojové učení. Databáze nabízí techniky správy dat, zatímco strojové učení nabízí techniky analýzy dat. K implementaci technik strojového učení však používal algoritmy.
- Dolování dat používá více dat k získání užitečných informací a tato konkrétní data pomohou předpovídat některé budoucí výsledky, například v obchodní společnosti, která používá data z minulého roku k předpovídání tohoto prodeje, ale strojové učení se příliš nespoléhá na data, která používá algoritmy, například, OLA, UBER techniky strojového učení pro výpočet ETA pro jízdy.
- Schopnost samoučení není přítomna při těžbě dat, řídí se pravidly a předdefinována. Poskytne řešení pro konkrétní problém, ale algoritmy strojového učení jsou samy definovány a mohou změnit svá pravidla podle scénáře, najde řešení pro konkrétní problém a řeší jej vlastním způsobem.
- Hlavním a nejdůležitějším rozdílem mezi těžbou dat a strojovým učením je to, že bez zapojení těžby lidských dat nemůže fungovat, ale do strojového učení je lidské úsilí zapojeno pouze v době, kdy je definován algoritmus, který poté, co je implementován, uzavře všechno vlastními prostředky navždy použít, ale to není případ těžby dat.
- Výsledek produkovaný strojovým učením bude přesnější ve srovnání s těžbou dat, protože strojové učení je automatizovaný proces.
- Dolování dat používá databázi nebo server datového skladu, technik dolování dat a techniky vyhodnocování vzorů k získání užitečných informací, zatímco strojové učení používá neuronové sítě, prediktivní model a automatizované algoritmy pro rozhodování.
Porovnání tabulky těžby dat vs. strojového učení
| základní pro srovnání | Dolování dat | Strojové učení |
| Význam | Získávání znalostí z velkého množství dat | Zavést nový algoritmus z dat i minulé zkušenosti |
| Dějiny | Představujeme v roce 1930, původně označované jako objev znalostí v databázích | představit v blízkosti 1950, první program byl Samuel je kontrola-hrát program |
| Odpovědnost | Dolování dat se používá k získání pravidel ze stávajících dat. | Strojové učení učí počítač učit se a rozumět daným pravidlům. |
| Původ | Tradiční databáze s nestrukturovanými daty | Existující data i algoritmy. |
| Implementace | Můžeme vyvinout vlastní modely, pro které můžeme použít techniky těžby dat | Algoritmus strojového učení můžeme použít ve stromu rozhodování, neuronových sítích a některé další oblasti umělé inteligence. |
| Příroda | Zapojuje lidské rušení více do manuálu. | Automatizovaný, jakmile je návrh implementován samostatně, žádné lidské úsilí |
| aplikace | používá se v clusterové analýze | používá se při vyhledávání na webu, spamový filtr, hodnocení kreditu, detekce podvodů, počítačový design |
| Abstrakce | Abstrakt těžby dat ze skladu dat | Strojové učení čte stroj |
| Techniky zahrnují | Dolování dat je spíše výzkum využívající metody, jako je strojové učení | Naučil se a trénuje systém, aby plnil inteligentní úkol. |
| Rozsah | Aplikováno v omezené oblasti | Lze použít v rozsáhlé oblasti. |
Závěr - Dolování dat vs. Strojové učení
Ve většině případů se nyní dolování dat používá k predikci výsledku z historických dat nebo k nalezení nového řešení ze stávajících dat. Většina organizace používá tuto techniku k dosažení obchodních výsledků. Tam, kde techniky strojového učení rostou mnohem rychleji, protože překonávají problémy s tím, co mají techniky těžby dat. Vzhledem k tomu, že proces strojového učení je přesnější a méně náchylný k chybám ve srovnání s těžbou dat a je mnohem schopnější přijmout své vlastní rozhodnutí a vyřešit problém. Abychom však stále podnikali, potřebujeme proces těžby dat, protože bude definovat problém konkrétního podniku a tento problém můžeme vyřešit pomocí technik strojového učení. Jedním slovem můžeme říci, že pro řízení podniku musí dolování dat a techniky strojového učení pracovat ruku v ruce, jedna technika bude definovat problém a druhá vám poskytne řešení mnohem přesnějším způsobem.
Doporučený článek
Toto byl průvodce těžbou dat vs. strojovým učením, jejich významem, porovnáváním mezi hlavami, klíčovými rozdíly, srovnávací tabulkou a závěrem. Další informace naleznete také v následujících článcích -
- 8 Důležité techniky dolování dat pro úspěšné podnikání
- 7 Důležité techniky dolování dat pro dosažení nejlepších výsledků
- 5 nejlepších rozdílů mezi strojem Big Data Vs Machine Learning
- 5 nejužitečnější rozdíl mezi datovou vědou a strojovým učením