

Rozdíl mezi Hadoopem a HBase
Hadoop je open-source Java framework, používaný pro správu a zpracování velkého množství strukturovaných a nestrukturovaných dat. Hadoop je masivně škálovatelný, proto se používá ke zpracování velkých datových zatížení. Velká data jsou ukládána, přístupná a zpracovávána ve spolehlivém a rozšiřitelném clusteru. HBase (Hadoop Database) je non-relační a nejen SQL, tj. NoSQL databáze, která běží na vrcholu Hadoop jako distribuované a škálovatelné velké datové úložiště. Je to open-source databáze, ve které jsou data uložena ve formě řádků a sloupců, v této buňce je průnik sloupců a řádků.
Níže jsou hlavní komponenty architektury Hadoop:
- Distribuovaný systém souborů Hadoop (HDFS): Hadoop zahrnuje distribuovaný systém úložišť, distribuovaný systém souborů Hadoop (HDFS). HDFS je architektura master-slave, která ukládá data v klastru. Data distribuovaná na několika podřízených uzlech hlavním uzlem ve formuláři. Hlavní uzel se nazývá Namenode a slave uzly se nazývají Datanode. HDFS je snadno rozšiřitelný a ukládá obrovské množství dat na Datanodes. HDFS má konfigurovatelný replikační faktor s výchozí hodnotou 3, kterou lze upravit.
- MapReduce: MapReduce je programovací paradigma, které probíhá paralelně na velkém počtu datových sad v síti. MapReduce odkazuje na dva různé úkoly: mapování vstupních dat, ve kterých data rozdělená do podmnožiny dat zvaných jako n-tice a úloha snižování, vezme tyto n-tice z mapy jako vstup a kombinuje se tak, aby vytvořila výstup originálu.
- Příze: YARN je zkratka pro ještě další prostředek navigátor, který výpočetní prostředky, jako je správa CPU a paměti, plánování požadavků na zdroje.
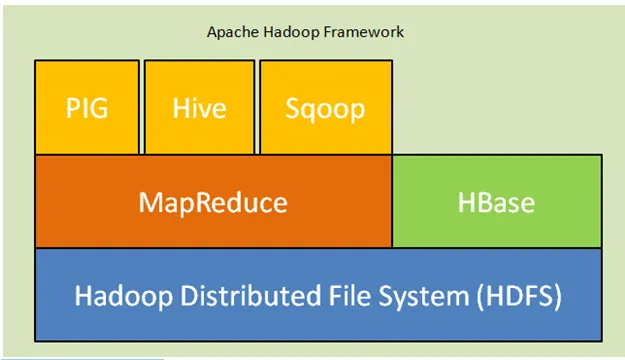
Obr. Apache Hadoop Framework
Regionální server poskytuje data pro operace čtení a zápisu. Všechna data HBase jsou uložena v souboru HDFS. Datový kód HDFS ukládá data, která spravuje server Region. Namenode HDFS uchovává informace o metadatech pro všechny bloky fyzických dat, které obsahují soubory.
Vytváření verzí se používá ke sledování změn buněk, které udržují přehled o verzi obsahu. Z toho lze získat libovolnou verzi obsahu. Každá hodnota buňky obsahuje atribut 'version' s ohledem na časové razítko pro načtení buňky. Každá hodnota na mapě je nepřetržitým polem bajtů. Mapa je indexována pomocí klíče řádku, klíče sloupce a časového razítka. Architektura HBase jsou vysoce škálovatelné, řídké, distribuované, trvalé a vícerozměrné mapy.
Srovnání mezi hlavami mezi Hadoopem a HBase (infografika)
Níže je seznam nejlepších 7 rozdílů mezi Hadoopem a HBase
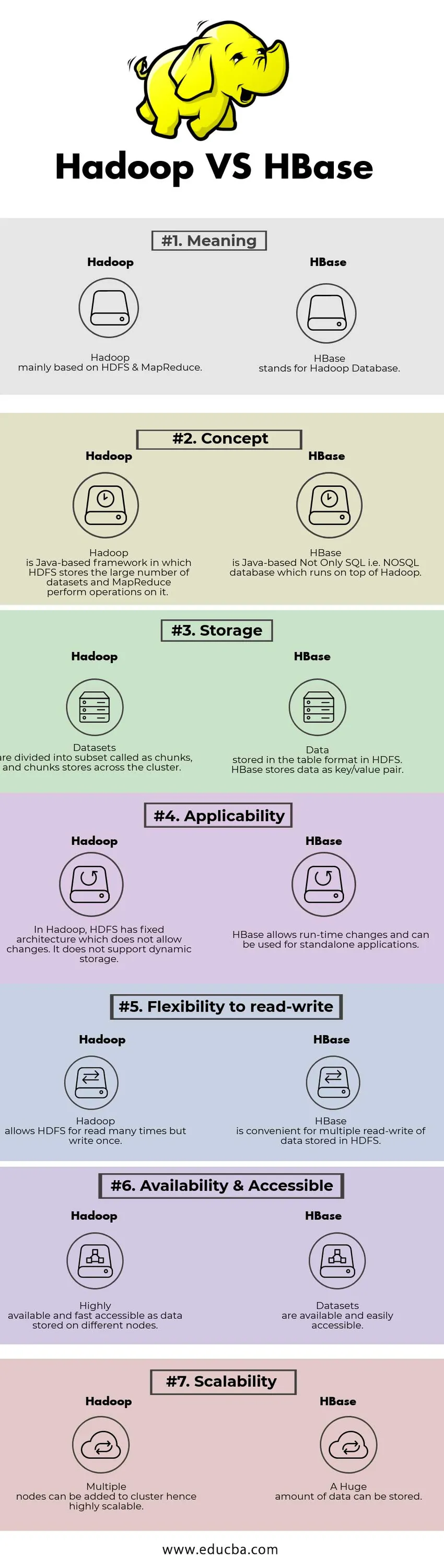
Klíčové rozdíly mezi Hadoopem a HBase
Rozdíl mezi Hadoop a HBase je vysvětlen v následujících bodech:
- Hadoop není vhodný pro online analytické zpracování (OLAP) a HBase je součástí ekosystému Hadoop, který poskytuje náhodný přístup v reálném čase (čtení / zápis) k datům v souborovém systému Hadoop.
- Hadoop framework je konstrukčně odolný vůči chybám a podporuje rychlý přenos dat mezi uzly i při selhání systému. HBase je nerelační a open source databáze typu Not-Only-SQL, která běží nad Hadoopem. HBase spadá pod CP typ CAP (věta o konzistenci, dostupnosti a toleranci oddílů).
- Hadoop je nejvhodnější pro provádění dávkové analýzy. Jednou z jeho největších nevýhod je však neschopnost provádět analýzu v reálném čase, což je trend v IT průmyslu. HBase, na druhé straně, zvládne velké soubory dat a není vhodný pro dávkovou analýzu. Místo toho se používá k zápisu / čtení dat z Hadoop v reálném čase.
- Hadoop i HBase jsou schopny zpracovávat strukturovaná, polostrukturovaná i nestrukturovaná data. V Hadoopu HDFS postrádá modul pro zpracování v paměti, který zpomaluje proces analýzy dat; protože to používá obyčejný MapReduce. HBase se naopak může pochlubit motorem pro zpracování v paměti, který drasticky zvyšuje rychlost čtení / zápisu.
- Hadoop je velmi transparentní při provádění analýzy dat. Na druhou stranu HBase je databáze NoSQL v tabulkovém formátu a načítá hodnoty tříděním podle různých klíčových hodnot.
Srovnávací tabulka Hadoop vs HBase
| ZÁKLAD PRO SROVNÁNÍ | Hadoop | HBase |
| Význam | Hadoop založený hlavně na HDFS a MapReduce. | HBase je zkratka pro databázi Hadoop. |
| Pojem | Hadoop je framework založený na Javě, ve kterém HDFS ukládá velké množství datových sad a MapReduce s ním provádí operace. | HBase je Java-založené nejen SQL, tj. NoSQL databáze, která běží na Hadoop. |
| Úložný prostor | Datové sady jsou rozděleny do podmnožiny nazývané kusy a kusy jsou ukládány v klastru. | Data uložená ve formátu tabulky v HDFS. HBase ukládá data jako pár klíč / hodnota. |
| Použitelnost | V Hadoopu má HDFS pevnou architekturu, která neumožňuje změny. Nepodporuje dynamické úložiště. | HBase umožňuje změny za běhu a lze je použít pro samostatné aplikace. |
| Flexibilita čtení a zápisu | Hadoop umožňuje HDFS mnohokrát číst, ale psát jednou. | HBase je vhodný pro vícenásobné čtení a zápis dat uložených v HDFS |
| Dostupnost a přístupnost | Vysoce dostupné a rychle přístupné jako data uložená na různých uzlech. | Datové sady jsou dostupné a snadno dostupné |
| Škálovatelnost | Do clusteru lze přidat více uzlů, a proto je vysoce škálovatelné. | Lze uložit obrovské množství dat. |
Závěr - Hadoop vs HBase
Hadoop architektura založená hlavně na HDFS a MapReduce. HBase je podpůrnou součástí systému Hadoop. HBase je schopen hostit obrovské tabulky a poskytuje rychlý náhodný přístup k dostupným datům, zatímco HDFS je vhodný pro ukládání velkých souborů. Hadoop i HBase poskytují rychlý přístup k datům, ale pomocí HBase lze provádět operace čtení / zápis a pro HDFS mnohokrát a jednou lze provést zápis. Tento článek popisuje porozumění Hadoop a HBase, stručně vyzdvihuje funkce a moudře je srovnává.
Doporučený článek
- Apache Hadoop vs Apache Spark | Top 10 srovnání, které musíte znát!
- Hadoop vs Hive - Zjistěte nejlepší rozdíly
- HBase vs Cassandra - který z nich je lepší (Infografika)
- Top 12 Porovnání Apache Hive vs Apache HBase (Infographics)
- Hadoop vs Spark: Jaké jsou funkce