
Co je lineární regrese v R?
Lineární regrese je nejoblíbenější a nejrozšířenější algoritmus v oblasti statistiky a strojového učení. Lineární regrese je modelovací technika k pochopení vztahu mezi vstupními a výstupními proměnnými. Zde musí být proměnné číselné. Lineární regrese vychází ze skutečnosti, že výstupní proměnná je lineární kombinací vstupních proměnných. Výstup je obvykle reprezentován „y“, zatímco vstup je reprezentován „x“.
Lineární regrese v R lze rozdělit do dvou způsobů
-
Silná lineární regrese
Toto je regrese, kde je výstupní proměnná funkcí jediné vstupní proměnné. Reprezentace jednoduché lineární regrese:
y = c0 + c1 * x1
-
Vícenásobná lineární regrese
Toto je regrese, kde výstupní proměnná je funkcí proměnné s více vstupy.
y = c0 + c1 * x1 + c2 * x2
V obou výše uvedených případech c0, c1, c2 jsou koeficienty, které představují regresní váhy.
Lineární regrese v R
R je velmi silný statistický nástroj. Podívejme se, jak lze v R provést lineární regresi a jak lze interpretovat její výstupní hodnoty.
Pojďme připravit dataset, abychom nyní provedli a pochopili lineární regresi do hloubky.
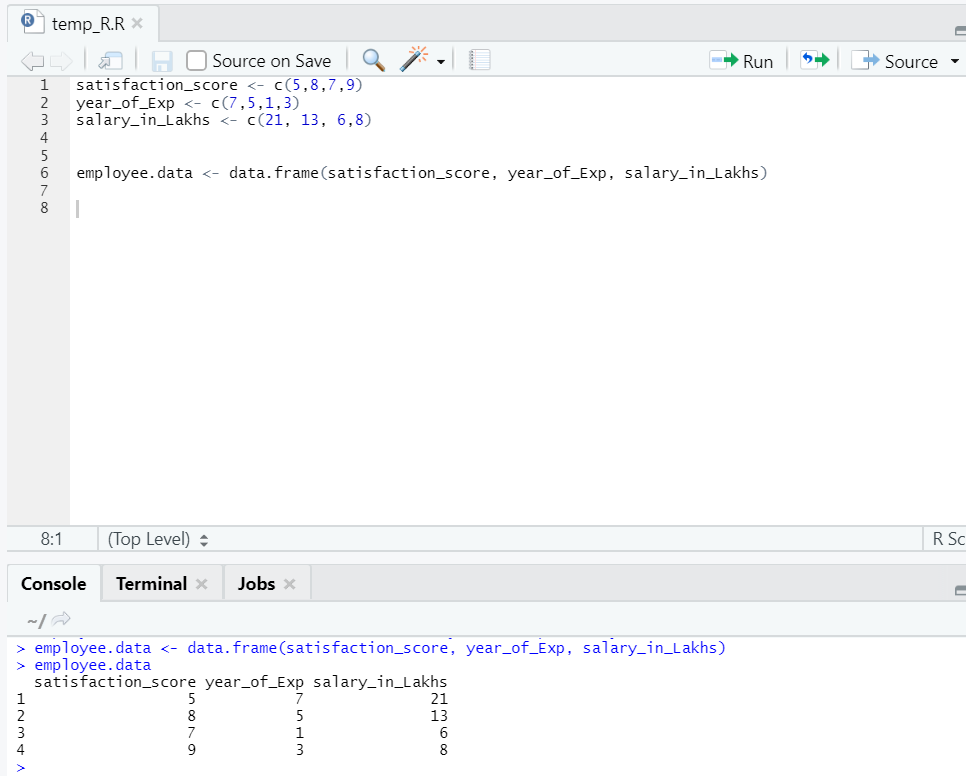
Nyní máme dataset, kde nezávislá proměnná jsou „satisf_score“ a „year_of_Exp“. „Salary_in_lakhs“ je výstupní proměnná.
Pokud jde o výše uvedený datový soubor, problém, který zde chceme řešit pomocí lineární regrese, je:
Odhad mezd zaměstnance na základě jeho roku zkušeností a skóre spokojenosti v jeho společnosti.
R kód lineární regrese:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
Výstupem výše uvedeného kódu bude:
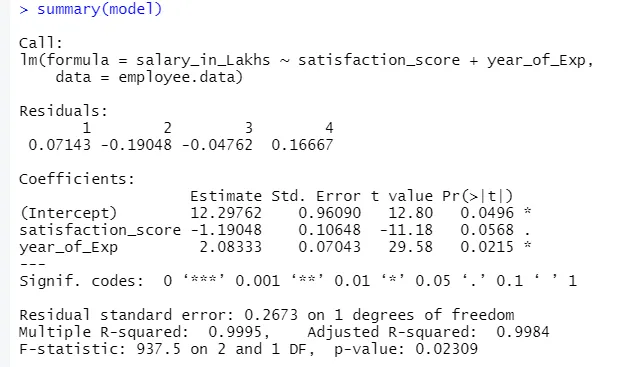
Vzorec regrese se stává
Y = 12, 29-1, 19 * satisf_score + 2, 08 × 2 * year_of_Exp
V případě, že jeden má více vstupů do modelu.
Pak R kód může být:
model <- lm (salary_in_Lakhs ~., data = employee.data)
Pokud však někdo chce vybrat proměnnou z více vstupních proměnných, existuje několik technik, jako je „zpětná eliminace“, „přeposílání vpřed“ atd., Které jsou k dispozici také.
Interpretace lineární regrese v R
Níže jsou uvedeny některé interpretace lineární regrese v r, které jsou následující:
1.Zbytky
To se týká rozdílu mezi skutečnou odpovědí a předpokládanou odpovědí modelu. Pro každý bod tedy existuje jedna skutečná odpověď a jedna předpovězená odpověď. Zbytky tedy budou tolik jako pozorování. V našem případě máme čtyři pozorování, tedy čtyři zbytky.

2.Výsledky
Jdeme dále, najdeme sekci koeficientů, která zobrazuje průnik a sklon. Pokud chce člověk předvídat plat zaměstnance na základě jeho zkušeností a skóre spokojenosti, je třeba vyvinout modelový vzorec založený na sklonu a zastavení. Tento vzorec vám pomůže při předpovídání platu. Zachycení a sklon pomáhají analytikovi přijít s nejlepším modelem, který nejlépe vyhovuje datovým bodům.
Slope: Zobrazuje strmost linie.
Intercept: Místo, kde čára řezá osu.
Pojďme pochopit, jak se formule formuje na základě sklonu a zastavení.
Řekněte, že je přestávka 3 a sklon 5.
Vzorec je tedy y = 3 + 5x . To znamená, že pokud se x zvýší o jednotku, y se zvýší o 5.
a.Cofficient - odhad
V tomto případě přestávka označuje průměrnou hodnotu výstupní proměnné, když je veškerý vstup nulový. V našem případě tedy bude plat v jezerech 12, 29Lachů, protože průměrné hodnocení spokojenosti a zkušenosti jsou nulové. Zde sklon představuje změnu ve výstupní proměnné s jednotkovou změnou ve vstupní proměnné.
b.Coefficient - Standard Error
Standardní chyba je odhad chyby, kterou můžeme získat při výpočtu rozdílu mezi skutečnou a předpovězenou hodnotou naší proměnné odezvy. To zase říká o důvěryhodnosti souvisejících vstupních a výstupních proměnných.
c.Cofficient - t value
Tato hodnota dává důvěru k odmítnutí nulové hypotézy. Čím větší je hodnota od nuly, tím větší je důvěra v odmítnutí nulové hypotézy a vytvoření vztahu mezi výstupem a vstupní proměnnou. V našem případě je hodnota také od nuly.
d.Cofficient - Pr (> t)
Tato zkratka v podstatě zobrazuje p-hodnotu. Čím blíže je nule, tím snáze můžeme odmítnout nulovou hypotézu. Řádek, který vidíme v našem případě, je tato hodnota téměř nulová, můžeme říci, že existuje vztah mezi platovým balíčkem, skóre spokojenosti a rokem zkušeností.

Zbytková standardní chyba
To zobrazuje chybu v predikci proměnné odezvy. Čím nižší je, tím vyšší je přesnost modelu.
Více na druhou, upravená na druhou
R-kvadrát je velmi důležité statistické měřítko pro pochopení toho, jak blízko jsou data do modelu vložena. V našem případě tedy, jak dobře náš model, který je lineární regresí, představuje datový soubor.
Hodnota R na druhou je vždy mezi 0 a 1. Vzorec je:

Čím je hodnota blíže 1, tím lépe model popisuje datové sady a jejich rozptyl.
Pokud však do obrázku vstoupí více než jedna vstupní proměnná, upřednostňuje se upravená hodnota R na druhou.
F-Statistic
Je to silné měřítko k určení vztahu mezi proměnnou vstupu a odezvy. Čím větší je hodnota než 1, tím vyšší je důvěra ve vztah mezi vstupní a výstupní proměnnou.
V našem případě je to „937, 5“, což je vzhledem k velikosti dat relativně větší. Odmítnutí nulové hypotézy je proto snazší.
Pokud chce někdo vidět interval spolehlivosti pro koeficienty modelu, je to způsob, jak to udělat: -
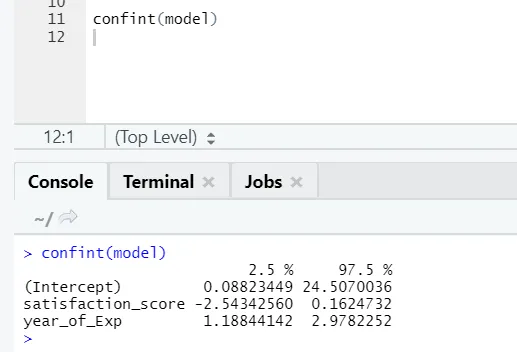
Vizualizace regrese
R kód:
plot (salary_in_Lakhs ~ satisf_score + year_of_Exp, data = employee.data)
abline (model)
Je vždy lepší získat více a více bodů, než se přizpůsobíte modelu.
Závěr - lineární regrese v R
Lineární regrese je jednoduchá, snadno se přizpůsobí, snadno pochopitelná a přesto velmi výkonná. Viděli jsme, jak lze provést lineární regresi na R. Zkoušeli jsme také interpretaci výsledků, což vám může pomoci při optimalizaci modelu. Jakmile si člověk osvojí jednoduchou lineární regresi, měli bychom zkusit více lineární regresi. Spolu s tím, protože lineární regrese je citlivá na odlehlé hodnoty, je třeba se na ni dívat, než skočí přímo do fitingu na lineární regresi.
Doporučené články
Toto je průvodce po lineární regresi v R. Zde diskutujeme o tom, co je lineární regrese v R? kategorizace, vizualizace a interpretace R. Další informace naleznete také v našich dalších navrhovaných článcích -
- Prediktivní modelování
- Logistická regrese v R
- Rozhodovací strom v R
- R Otázky k pohovoru
- Největší rozdíly regrese vs. klasifikace
- Průvodce rozhodovacím stromem ve strojovém učení
- Lineární regrese vs. logická regrese Nejlepší rozdíly