
Úvod do souboru technik
Ensemble learning je technika ve strojovém učení, která využívá několik základních modelů a kombinuje jejich výstup a vytváří optimalizovaný model. Tento typ algoritmu strojového učení pomáhá při zlepšování celkového výkonu modelu. Základní model, který se nejčastěji používá, je klasifikátor stromu rozhodnutí. Rozhodovací strom v podstatě pracuje na několika pravidlech a poskytuje prediktivní výstup, kde jsou pravidla uzly a jejich rozhodnutí budou jejich děti a uzly listů budou konečným rozhodnutím. Jak je ukázáno na příkladu stromu rozhodování.
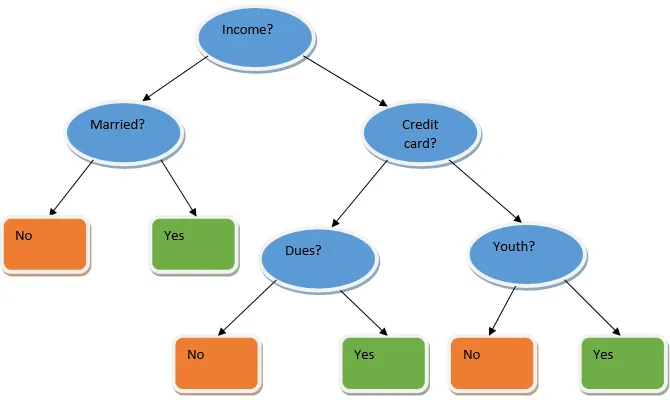
Výše uvedený strom rozhodování v zásadě hovoří o tom, zda lze osobě / zákazníkovi získat půjčku nebo ne. Jedním z pravidel pro způsobilost k úvěru ano je to, že pokud (příjem = Ano && Ženatý = Ne), pak půjčka = Ano, takže takto funguje klasifikátor rozhodovacích stromů. Budeme začlenit tyto klasifikátory jako vícenásobný základní model a kombinovat jejich výstupy tak, abychom vytvořili jeden optimální prediktivní model. Obrázek 1.b ukazuje celkový obrázek algoritmu kompletního učení.
Typy technik souborů
Různé typy souborů, ale hlavní důraz bude kladen na níže uvedené dva typy:
- Pytlování
- Posílení
Tyto metody pomáhají při snižování rozptylu a zkreslení v modelu strojového učení. Nyní se pokusme pochopit, co je zaujatost a rozptyl. Předpojatost je chyba, ke které dochází v důsledku nesprávných předpokladů v našem algoritmu; vysoká předpojatost znamená, že náš model je příliš jednoduchý / nevyhovující. Varianta je chyba způsobená citlivostí modelu na velmi malé výkyvy v sadě dat; vysoká rozptyl značí, že náš model je vysoce komplexní / přeplněný. Ideální ML model by měl mít správnou rovnováhu mezi zaujatostí a rozptylem.
Agregace / pytlování Bootstrap
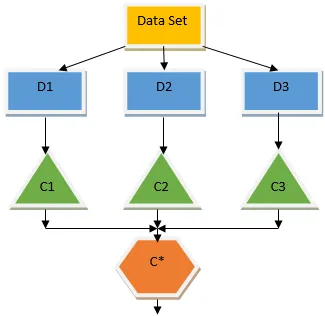
Bagging je technika souboru, která pomáhá při snižování rozptylu v našem modelu, a proto se vyhýbá přeplnění. Bagging je příkladem algoritmu paralelního učení. Pytlovací práce založená na dvou principech.
- Bootstrapping: Z původního souboru dat se uvažuje s nahrazením různých vzorků.
- Agregace: Zprůměrování výsledků všech klasifikátorů a poskytnutí jediného výstupu, pro tento účel používá většinové hlasování v případě klasifikace a průměrování v případě regresního problému. Jedním ze slavných algoritmů strojového učení, které používají koncept pytlování, je náhodný les.
Náhodný les
V náhodném lese z náhodného vzorku odebraného z populace s nahrazením a podmnožina prvků je vybrána ze sady všech prvků, která je vytvořena rozhodovacím stromem. Z těchto podmnožin funkcí je vybrána kterákoli funkce, která dává nejlepší rozdělení, jako kořen stromu rozhodování. Podmnožina prvků musí být vybrána náhodně za každou cenu, jinak budeme nakonec vyrábět pouze korelovaný tress a rozptyl modelu se nezlepší.
Nyní jsme sestavili náš model se vzorky odebranými z populace, otázkou je, jak tento model validujeme? Protože zvažujeme vzorky s náhradou, nebudou všechny vzorky brány v úvahu a některé z nich nebudou zahrnuty do žádného sáčku. Můžeme ověřit náš model pomocí těchto vzorků OOB (mimo sáček). Důležitými parametry, které je třeba brát v úvahu v náhodném lese, je počet vzorků a počet stromů. Uvažujme 'm' jako podmnožinu funkcí a 'p' je úplná sada funkcí, nyní jako pravidlo, je vždy ideální zvolit
- m as√a minimální velikost uzlu 1 jako problém klasifikace.
- m jako P / 3 a minimální velikost uzlu 5 pro regresní problém.
M a p by se měli považovat za parametry ladění, když se zabýváme praktickým problémem. Po stabilizaci chyby OOB může být trénink ukončen. Jednou z nevýhod náhodné struktury je, že když v naší datové sadě máme 100 funkcí a je důležité pouze několik funkcí, bude tento algoritmus fungovat špatně.
Posílení
Posílení je algoritmus sekvenčního učení, který pomáhá při snižování zkreslení v našem modelu a rozptylu v některých případech učení pod dohledem. Pomáhá také při přeměně slabých studentů na silné studenty. Posílení funguje na principu postupného umisťování slabých studentů a každému datovému bodu přiřadí váhu po každém kole; větší váha je přiřazena nesprávně klasifikovanému datovému bodu v předchozím kole. Tato postupná vážená metoda nácviku naší sady dat je klíčovým rozdílem od metody pytlování.
Obr. 3a ukazuje obecný přístup při posilování
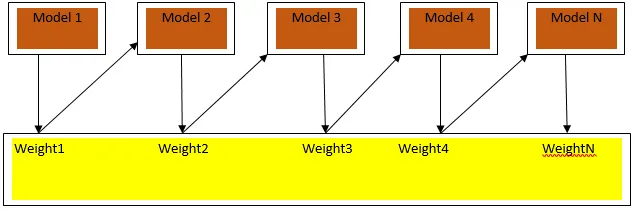
Konečné předpovědi se kombinují na základě hlasování váženou většinou v případě klasifikace a vážené částky v případě regrese. Nejčastěji používaným posilovacím algoritmem je adaptivní posilování (Adaboost).
Adaptivní zvýšení
Kroky zahrnuté v algoritmu Adaboost jsou následující:
- Pro dané n datové body definujeme cílovou nóbl a inicializujeme všechny váhy na 1 / n.
- Klasifikátory přizpůsobíme datové sadě a zvolíme klasifikaci s nejmenší váženou chybou klasifikace
- Hmotnosti klasifikátoru přiřazujeme palcovým pravidlem založeným na přesnosti, pokud je přesnost větší než 50%, pak je hmotnost kladná a naopak.
- Na konci iterace aktualizujeme hmotnosti klasifikátorů; aktualizujeme větší váhu pro nesprávně klasifikovaný bod, takže v následující iteraci jej klasifikujeme správně.
- Po celé iteraci získáme konečný výsledek predikce na základě většinového hlasování / váženého průměru.
Adaboosting pracuje efektivně se slabými (méně složitými) studenty as klasifikátory s vysokou zaujatostí. Hlavními výhodami Adaboostingu je to, že je rychlý, neexistují žádné ladicí parametry podobné případu pytlování a neděláme žádné předpoklady pro slabé studenty. Tato technika neposkytne přesný výsledek, když
- V našich datech je více odlehlých hodnot.
- Soubor dat je nedostatečný.
- Slabí studenti jsou velmi komplexní.
Jsou také citlivé na hluk. Rozhodovací stromy, které jsou produkovány jako výsledek posilování, budou mít omezenou hloubku a vysokou přesnost.
Závěr
Ke zlepšení přesnosti modelu se široce používají techniky učení souboru; musíme se rozhodnout, kterou techniku použijeme na základě našeho souboru dat. Tyto techniky však nejsou preferovány v některých případech, kdy je interpretovatelnost důležitá, protože ztrácíme interpretovatelnost na úkor zlepšení výkonu. Ty mají obrovský význam ve zdravotnickém průmyslu, kde je velmi cenné malé zlepšení výkonu.
Doporučené články
Toto je průvodce Ensemble Techniques. Zde diskutujeme úvod a dva hlavní typy technik Ensemble. Další informace naleznete také v dalších souvisejících článcích.
- Steganografické techniky
- Techniky strojového učení
- Techniky budování týmu
- Algoritmy pro vědu o datech
- Nejpoužívanější techniky učení souboru